Don't Learn C the Wrong Way
Update: On Sep. 28, 2015, Zed Shaw wrote a rebuttal to this post. You can find the details here.
Across the vastness of the internet, there are many resources for aspiring programmers to learn to program. Nowadays you can find the answer to most common questions with a simple Google search. Before this explosion of post-modern data availability, information was disseminated in the form of the written word.
Recently, I came across an e-book written by Zed A. Shaw entitled Learn C The Hard Way, and while I can commend the author for spending the time and energy to write it, I would NOT recommend it to anyone seriously interested in learning the C programming language. In fact, if you were one of the unlucky souls who happened to have purchased it. Go right now and at least try to get your money back!
In the same vein of the author's own "critique" of The C Programming Language, 2nd Ed. , which I'll hereafter also refer to as "K&R2", I'm going to critique the author's own work. Although, from what I've read the author has little stomach for criticism.
Let me start by saying that unlike Mr. Shaw, I am not a writer. I'm an engineer. Thus, this will be written from that perspective. All I would ask of those who read this, is to keep an open mind, and try to analyze the issues from a logical, dispassionate, and slightly and sarcastically humorous point of view.
As programmers/engineers/whatever-the-hell-people-call-us-these-days, accepting criticism is something we have to face every day. With the explosion of the open source movement, there are opportunities by-and-large to make something and have it peer reviewed by people who have a lifetime of experience and wealth of knowledge in the industry.
But, also, in our work lives, criticism comes with the job. Personally, I consider it to be a necessary skill in the work place to be able to accept constructive criticism. My attitude towards it is:
If you believe there's something wrong with my work, prove it so that it can be improved, and I can learn from the experience. However, I still reserve the right to point it out if your arguments are baseless.
I do take pride in my work, as we all should, but I don't take it personally. I expect that anyone who gives criticism should be able to receive just the same.
The whole point of this article is this: Don't learn C the wrong way. Do your own research, learn as much as you can, read K&R2, dig around and read other people's code, ask questions on IRC, etc. Don't just take anyone's word for it, not even mine.
TL;DR - To summarize my views, which are laid out below, the author presents the material in a greatly oversimplified and misleading way, the whole damn corpus is a bundled mess, and some of the opinions and analyses he offers are just plain wrong. I've tried to view this book through the eyes of a novice, but unfortunately I am biased by years of experience writing code in C. It's obvious to me that either the author has a flawed understanding of C, or he's deliberately oversimplifying to the point where he's actually misleading the reader (intentionally or otherwise.)
It's also unclear which standard of C the author is targeting. In the beginning it looks like it could be ANSI C. Further on, in "Exercise 20: Zed's Awesome Debug Macros" you can see that these are variadic macros which were introduced in C99.
I'm going to analyze the first few parts of the book, then skip to the end, and give a commentary on the author's rant against K&R2. What I find to be really sad, is that despite the author's best intentions, this book is really lacking enough information to be a useful resource for a novice developer. These missing concepts are well discussed in K&R2.
At the end of this piece, I'll give some final thoughts.
Part 1: The Introduction
Now, let's begin ith the introduction. First, a quote from Descartes, then a paragraph with the insinuation that most programmers are somehow afraid of C, likening it to "... the Devil, Satan, the trickster Loki." and a "computational Lucifer" with whom you must make sordid pacts to be productive. While I'm certain there are many people who are in fact afraid of writing in C, I'm certain that their apprehension stems from inexperience and a lack of specific domain knowledge rather than emotional fear.
It's true that one must be more aware of what they're doing in C, than in higher-level languages. With greater power comes greater responsibility. The higher-level languages to which a lot of aspiring C programmers are accustomed, such as Ruby and Python, provide abstraction layers that handle a lot of things for you. In C, you have much more control over what your program is doing, and also much more potential for breakage. To the uninitiated: Keep in mind that both Ruby and Python are in fact written in C.
The author apparently feels that writing code in C is inherently dangerous, but that writing code in more abstract languages makes one inherently stupid. Perhaps he meant to say, ignorance?
It's an ironic quote, considering the author has published two other works dedicated to higher-level languages:
The C programming language's only failing is giving you access to what is really there, and telling you the cold hard raw truth. C gives you the red pill. C pulls the curtain back to show you the wizard. C is truth.Why use C then if it's so dangerous? Because C gives you power over the false reality of abstraction and liberates you from stupidity.
-- Zed A. Shaw, "Learn C The Hard Way", Introduction
I'm not going to say too much about the rest of this section, it's not terribly interesting. Mainly the same sort of introductory filler you'll find in any "How-To" book.
Part 2: The Setup
Reading this section, I do agree with the last sentence in this block:
You can write C code for Windows, that's not a problem. The problem is all of the libraries, functions, and tools are just a little "off" from everyone else in the C world. C came from Unix and is much easier on a Unix platform.-- Zed A Shaw, "Learn C The Hard Way", Exercise 0: The Setup
C was designed on UNIX, and was basically made for UNIX. That's a matter of historical record. But to say that on Windows everything is a little "off", doesn't quite do it justice. I understand that the book is aimed at the uninitiated, but to put it that mildly is an understatement of epic proportions.
When it comes to setup instructions, it doesn't appear that the author went to any length to describe how one's environment should be set-up. In my opinion, second only to the importance of learning the language itself is knowing how to use it within your environment. For Mac OS X, the author writes:
... search online for "installing xcode" for instructions on how to do it.-- Zed A Shaw, "Learn C The Hard Way", Exercise 0: The Setup - Mac OS X
Isn't that great folks? The author of a "How-To" book says, "Google it!" as to how you should setup your environment. The Winblows users are stuck with the empty promise of:
For Windows users I'll show you how to get a basic Ubuntu Linux system up and running in a virtual machine so that you can still do all of my exercises, but avoid all the painful Windows installation problems.... have to figure this one out.
-- Zed A Shaw, "Learn C The Hard Way", Exercise 0: The Setup - Windows
While it's true a lot of things on Windows are utterly painful (not to mention it's painful to look at,) there are POSIX-compatible environments for Windows, believe it or not. There's (still) good 'ol Cygwin. BSD isn't even mentioned, and apparently the only installation methods for Linux are apt-get and yum. :P
If I were a novice programmer and had purchased this book, I'd have a pretty good case of the red ass about right now if I didn't know how to set-up my own environment. The author goes on to lament that:
An IDE, or "Integrated Development Environment" will turn you stupid. They are the worst tools if you want to be a good programmer because they hide what's going on from you, and your job is to know what's going on. They are useful if you're trying to get something done and the platform is designed around a particular IDE, but for learning to code C (and many other languages) they are pointless.-- Zed A Shaw, "Learn C The Hard Way", Exercise 0: The Setup
Personally, I find that IDEs do hide too many things from you, (I'm a vim user actually) and if you get to used to relying on clicking a button to do things, you start to forget how to do certain things on the command line. However, this whole paragraph, like a lot of the opinions the author presents, is merely a fallacy. There are plenty of people getting things done all day long with IDEs, and as far as IDEs that support multiple programming languages, Eclipse comes to mind.
Part 3: Getting Acquainted with the Compiler
Finally, we start getting down to something concrete. The author kicks
things off with the cliché "Hello, World" example, which appears to be
intentionally lacking the #include <stdio.h> necessary to pull in
the puts function. Then prompts the user to invoke make to build
it.
**EDIT**: Some feedback I've received claims that I'm somehow ignorant of Make's implicit rules because of the wording in this next paragraph, and a little further on. Let me clarify. I am well-aware of make's implicit rules. Those who've felt the need to pick on this point are either being really pedantic (for which I congratulate you), or they're missing the point made later in the paragraph, in addition to the running "Jimmy Hoffa" joke -- which is an analogy for most of the "setup"-type instruction you would expect, that fail to appear in the author's book entirely or appear, confusingly later than the tools they correspond to. Besides, it should be wholly obvious to you that this bit is /my/ opinion, and not presented as a material fact. Besides, what's the point of being a critic if I can't have a little fun poking a little fun at it along the way?
Wait a tic... Where's the Makefile? I've got just about as much chance of finding it as the FBI does of finding Jimmy Hoffa. Am I just supposed to imagine it into existence? I find this to be really bad form on the author's part. He should have started by waking the user through invoking the C compiler to build it, explained the steps in brief, etc. at this point. He then goes on to explain what a compiler warning is, etc.
If I were a novice programmer reading this book, I would be completely lost as to how to build this "Hello World" program.
Part 4: Make is the new Python
Even the title of this section is wrong on so many levels. There's
absolutely no correlation between make and python. They're
two completely different things. Even in an attempt to oversimplify for
the purposes of explanatory imagery, why would write something so
blatantly confusing? What if the reader has no experience with Python
at all, and doesn't even know what it is? The author is making an
assumption here that not only is the reader a novice in terms of C, but
Python also.
...C is a different beast completely where you have to compile your source files and manually stitch them together into a binary that can run on its own. Doing this manually is a pain, and in the last exercise you just ran make to do it. -- Zed A. Shaw, "Learn C The Hard Way", Exercise 2: Make is your new Python
So, first we have no environment and a phantom Makefile. Now, we have
a section about make and still no Makefile. Now, the author continues
to say how using this non-existent environment of ours is really painful.
It appears he also forgot about the separation of responsibilities between
the compiler, assembler, and linker in most toolchains these days. Quite
an oversight for someone writing a presumably "modern" book.
The difference is, I'm going to show you smarter Makefile wizardry, where you don't have to specify every stupid little thing about your C program to get it to build. I won't do that in this exercise, but after you've been using "baby make" for a while, I'll show you "master make". -- Zed A. Shaw, "Learn C The Hard Way", Exercise 2: Make is your new Python
At this point, the only thing I can think is, "I'd just love for you to show me a damn working Makefile!" A novice will be thinking, "What the hell's a Makefile?" as the concept of a Makefile has not yet been introduced. Not to mention the fact that all the examples thus far have been broken, presumably to force the user to make a common mistake so that they learn from it, but this book's "benefit of the doubt" allowance is starting to run out.
Part 5: Formatted Printing
So, finally printf() gets introduced. The author fails, in my
opinion to explain what it actually does. This has the reader using
format strings before even explaining (even briefly) what a format
string is. This has become a repetitive theme in this book, and
if I were a novice, I'd find it very confusing. The code the author
presents here is pretty straight-forward. Keep in mind the declaration
of main here. It's the same style used in K&R2.
#include <stdio.h>
int main()
{
int age = 10;
int height = 72;
printf("I am %d years old.\n", age);
printf("I am %d inches tall.\n", height);
return 0;
}
At least this time, the author explains his example step-by-step. But I found the explanation a little tiring to read, and slightly confusing:
First you're including another "header file" called stdio.h. This tells the compiler that you're going to use the "standard Input/Output functions". One of those is printf.Then you're using a variable named age and setting it to 10.
Next you're using a variable height and setting it to 72. Then you use the printf function to print the age and height of the tallest 10 year old on the planet. In the printf you'll notice you're passing in a string, and it's a format string like in many other languages. After this format string, you put the variables that should be "replaced" into the format string by printf.-- Zed A. Shaw, "Learn C The Hard Way", Exercise 3: Formatted Printing
So, in summary, printf() takes something called a "format string,"
and some variables, gets the age and height of the tallest 10-year-old on
the planet, and replaces my variables. Hmm... That's a bit creepy.
Part 6: Introducing Valgrind
Let's recap. I don't know how to set-up my environment, this "Makefile" thing pulled a Jimmy Hoffa, and now I have to use this Valgrind thing, after I go download it and build it from source. Great...
While I think it's great the the author wants to teach the reader how to use tools that will help them find memory leaks, etc.; it'd be nice if he'd have spent a little more time helping the user set-up their environment and get their feet wet first.
Part 7: The Structure of a C Program
In this section, the author presents a simple program, and then breaks
it down line-by-line. I'd have expected this a bit earlier on. This bit
about the main function definition is just wrong:
ex5.c:4 A more complex version of the main function you've been using blindly so far. ... For the function to be totally complete it needs to return an int and take two parameters, an int for the argument count, and an array of char * strings for the arguments.-- Zed A. Shaw, "Learn C The Hard Way", Exercise 5: The Structure of A C Program
ISO/IEC 9899:2011 §5.1.2.2.1 states in pertinent part:
The function called at program startup is namedmain. ... It shall be defined with a return type ofintand with no parameters:int main(void) { /* ... */ }or with two parameters (referred to here as
argcandargv, though any names may be used as they are local to the function in which they are declared):int main(int argc, char *argv[]) { /* ... */ }
I find the explanation given in the standard to be much more clear. Again, the author is oversimplifying things. But to be fair, I've never written a book about C.
Part 8: Finally, format strings explained!
Seems to me that the author has a penchant for delivering information
a bit too late. It's in this section that format strings used by
printf are finally explained, along with some sample code, and a
brief explanation of data types (which the author terms
"variable types".)
This section also contains misleading information, such as:
String (Array of Characters)Declared with char name[], written with " characters, and printed with %s.
-- Zed A. Shaw, "Learn C The Hard Way", Exercise 6: Types of Variables
An array of characters and a string are two different things. According to ISO/IEC 9899:2011 §7.1.1, a string is:
A string is a contiguous sequence of characters terminated by and including the first null character.
Note the key phrase terminated by ... null character. "Zed" and "Shaw" are called character string literals, and thus, they will be implicitly null terminated. An array of characters need not be null terminated. Remember these definitions, they will be important later.
Here's an example from the standard that illustrates this difference.
In this example, s is a string, while t is not, as it is not
null terminated.
EXAMPLE 8: The declaration char s[] = "abc", t[3] = "abc"; defines ‘‘plain’’ char array objects s and t whose elements are initialized with character string literals. This declaration is identical to: char s[] = { 'a', 'b', 'c', '\0' }, t[] = { 'a', 'b', 'c' }; -- ISO/IEC 9899:2011 §6.7.9
Am I being pedantic? You're damn right I am. The difference in this
case can be very important. Further on in this bit, the author prompts
the user to trigger a segmentation fault by passing an invalid pointer
to printf, with no explanation as to what it is, or why it happens.
Honestly, I find this to be a recurring theme in this piece. The author
throws the reader a curveball without having even told them that a ball
even exists.
The next parts of the book contains more of the same.
Part 9: Data Types (part 2)
Now that the author is calling data types by the correct term, he's also again misleading the reader about what these types are. This is also the first place with any mention of integer signedness. This is almost completely wrong:
int Stores a regular integer, defaulting to 32 bits in size. double Holds a large floating point number. float Holds a smaller floating point number. char Holds a single 1 byte character. -- Zed A. Shaw, "Learn C The Hard Way", Exercise 21: Advanced Data Types
The sizes for the integer types are implementation-defined. This is why
we have limits.h. Hell, I can have a machine with 1024-bit long,
512-bit int, and 256-bit short; and it would be perfectly standards
compliant so long as I define the sizes appropriately in limits.h.
K&R2 Chapter 2 covers this quite nicely:
Each compiler is free to choose appropriate sizes for its own hardware, subject only to the restriction that shorts and ints are at least 16 bits, longs are at least 32 bits, and short is no longer than int, which is no longer than long.-- Kerninghan & Ritchie, The C Programming Language, Section 2.2
The author then goes on to discuss the exact-width types introduced in C99, operators, etc. In the next sections, the author covers scope, the stack, and even Duff's Device. Talk about confusing for a novice, who'd be thinking by this point, "Wait... Duff's Device... Is that some new kind of beer opener?"
Finally in "Exercise 26" you're supposed to write your own program. Even though you have no Makefile, you haven't found Jimmy Hoffa yet, and there's been hardly any explanation of how to invoke the compiler. So, I'm just supposed to poke in some code, go to my terminal, type this magic 'make' word, and expect a built and working program, right?
The latter parts of the book touch on using gdb, the linker,
make (finally in "Exercise 28" we get a Makefile), unit testing with
some weird macros, introducing some over-engineered, poorly-written
data structures, etc. Things like this
and this
and this
would be enough to make a C programmer cringe...
Part 10: Strings and Seething Hatred
One recurring piece of code I've seen the author pick at is this one:
void copy(char to[], char from[])
{
int i = 0;
while ((to[i] = from[i]) != '\0') {
i++;
}
}
It's referenced in "Exercise 27", again in "Exercise 36," and also at the heart of the author's opining tirade against K&R2 that I mentioned at the beginning of this article. This function is copied from K&R2 Chapter 1, Section 9 (pp. 29).
We'll look at the full example from K&R a bit later. For now, just keep in mind that this function is part of a larger example and is being interpreted out-of-context by the author. So, I'm going to play into that.
This function copies a string from from to to. Why is he picking
on this one particular function out of all the others in the book? He
writes:
When people talk about problems with C, it's concept of a "string" is one of the top flaws. You've been using these extensively, and I've talked about the kinds of flaws they have, but there's not much that explains exactly why C strings are flawed and always will be. I'll try to explain that right now, but part of my explanation will just be that after decades of using C's strings there's enough evidence that they are just a bad idea.It is impossible to confirm that any given C string is valid:
A C string is invalid if it does not end in '\0'.
Any loop that processes an invalid C string will loop infinitely (or, just buffer overflow).
C strings do not have a known length, so the only way to check if it's terminated correctly is to loop through it.
Therefore, it is not possible to validate a C string without possibly looping infinitely.
This is simple logic. You can't write a loop that checks if a C string is valid because invalid C strings cause loops to never terminate. That's it and the only solution is to include the size. Once you know the size you can avoid the infinite loop problem.
-- Zed A. Shaw, "Learn C The Hard Way", Exercise 36: Safer Strings
The last part is a complete load of bull! The author's logic here is
based on a false assumption that given a function which operates on a
string (e.g. strlen), he should be able to pass something that's
not a string as though it were, and not encounter some undefined
behavior. In fact this is his main supporting argument for why the
copy function is "broken." He's taken this idea, and has now
generalized it to "all C strings are broken."
The author seems to seethe with hatred toward C strings. Let's examine his arguments in greater detail, and look at the alternatives that he proposes.
A string is invalid if it isn't null-terminated. On this point, the author is 100% correct. As I quoted earlier, if it's not null terminated, it's not a string.
In general, the onus is on the caller to pass a valid parameter, not the callee. What this means, is that before calling the above K&R
copy()function, the caller should ensure that bothtoandfromare valid strings.strcpytakes a lot of heat for making it easy to cause buffer overflows in programs. This is why we havestrncpy()(glibc and derivatives) andstrlcpy()(BSD) which force the caller to pass the storage size (read: length) of the destination buffer. Even these safer alternatives can still lead to a buffer overflow if the passed length is wrong. So, in order to help further prevent overflows, the compiler guys added a feature calledSSP, or Stack-Smashing Protection years ago. In fact, it's now enabled by default in most commonly-used Linux distros for desktop and server environments, but it is compiler-dependent and certainly not perfect.Wrong. The length of a string is from the first byte to the null character. There are cases where you don't know the exact length of a string, but you should know the maximum storage size for said string. You should ensure that there's a null byte at the end before passing it to any function as a string.
Also wrong. Even if such a function was stuck in an "infinite loop" condition, it would eventually reach the end of the memory block and cause a segmentation fault, or depending on architecture may cause the CPU to lock-up, a watchdog timer to kill the process or reboot the system, a CPU/MMU exception to be triggered, or some signal to be asserted (e.g. ARM's data-abort exception, the ABORT signal on the 65816, a page fault exception, memory protection exception, invalid memory access exception, etc.)
The bottom line is -- it won't just run on forever in most practical cases. If '\0' exists nowhere in the CPUs entire address space, which is quite unlikely assuming that at least some part of memory was initialized to 0, then it may loop through all available memory, wrap around, and loop indefinitely, without causing any type of interrupt to be generated; assuming that it's possible to do it on that particular system without any sort of interrupt being generated. But, this is highly unlikely, although not impossible. It's far more likely that a '\0' will exist somewhere in memory, or that the process will be killed by the OS before it will loop indefinitely.
I could imagine this happening on a Z80, for example, the entire address space never contained a '\0'. But this would be an extreme edge-case, as you'd have to initialize all your RAM to something non-zero, and ensure that no zero byte exists in ROM (if present), or would be returned by reading any other address across the address space.
Now that the arguments have been refuted, let's look at his proposed alternatives. First, he proposes this function:
int safercopy(int from_len, char *from, int to_len, char *to)
{
int i = 0;
int max = from_len > to_len - 1 ? to_len - 1 : from_len;
// to_len must have at least 1 byte
if(from_len < 0 || to_len <= 0) return -1;
for(i = 0; i < max; i++) {
to[i] = from[i];
}
to[to_len - 1] = '\0';
return i;
}
While this may feel somewhat safer by doing some rudimentary checks on
the provided "lengths", it's certainly not safer than the K&R copy
function. For one, this function never checks the pointers to ensure
they're non-NULL, nor for the null byte at the end of from. It's
still possible to read past the end of from or write past the end
of to here.
The author goes on to say:
Imagine you want to add a check to the copy function to confirm that the from string is valid. How would you do that? Why you'd write a loop that checked that the string ended in '\0'. Oh wait, if the string doesn't end in '\0' then how does the checking loop end? It doesn't. Checkmate. -- Zed A. Shaw, "Learn C The Hard Way", Exercise 36: Safer Strings
Checkmate? I think not.
We can do a bit better by adding just a little bit of code to the K&R function. This function does check that the string ends in '\0', just like the original function. Neither will loop endlessly as the author claims. We can still cause undefined behvior in this function, which I'll explain a little further down.
void copy(char from[], char to[], size_t n)
{
size_t i = 0;
if (!from || !to) return;
while (i < n && (to[i] = from[i]) != '\0')
i++;
to[n] = '\0';
}
In this function, which is amazingly close to the original, I've added only two major things:
We assume that
fromandtoare valid strings. If either one isNULL, we take no action. We could be a bit more graceful here, checking from and to separately, and only executing thewhileloop if from is notNULLfalling through to truncatetoby writing the null byte toto[0]otherwise, but that's not necessary for this example. We assume that the size oftoisn, thus even iffromis not a valid string, this function will not write past the end ofto.This function, like
strlcpy, will always add a terminating null byte, even ifnis zero. A similar example is given in thestrncpy(3)manual page.
Instead of senselessly ranting against C strings, and how bad they suck, the author could have explained more about properly handling C strings.
Here's an example of this new-and-improved copy function in action:
#include <stdio.h>
/* The size of our buffer (in chars) */
#define BUF_SIZE 16
int main(int argc, char *argv[])
{
char to[BUF_SIZE];
/* This should print: "to is: this is a test" */
copy("this is a test", to, BUF_SIZE + 100);
printf("to is: %s\n", to);
/* This should print: "to is:" */
copy("of the emergency broadcast system", to, 0);
printf("to is: %s\n", to);
/* This should print: "to is: WARNING: Zombies ahead!" */
copy("WARNING: Zombies ahead!", to, -BUF_SIZE);
printf("to is: %s\n", to);
/* This should print: "to is: AAAABBBBCCCCDDD" */
copy("AAAABBBBCCCCDDDDEEEEFFFFGGGGHHHHIIII", to, BUF_SIZE - 1);
printf("to is: %s\n", to);
return 0;
}
The first invocation works because it finds the null byte in
from, since from is a valid string, and correctly exits the loop.The second works because we passed a length of zero. Thus, it simply overwrote the first byte of
towith a null byte, creating a correct zero-length string.The fourth invocation works because we passed the correct size, so the function didn't try to copy past the end of
to, and correctly null-terminated it.Why does the third invocation allow us to overrun the buffer? Well, that's because
size_tis unsigned (as are integers used as array indexes) and when converted from a signed number to an unsigned number,-BUF_SIZEbecomes(SIZE_MAX - BUF_SIZE - 1), due to integer promotion. Since it's never smaller thaniin this case, we wind up writing past the end ofto, and attempting to write the null byte into some address somewhere which may cause some side-effects (e.g. memory corruption, memory access exceptions, etc.)
Is that C's fault: No. Even if it may seem a little odd at first, this is defined behavior, which has been around since at least ANSI C.
... if the value can be represented by the new type, it is unchanged. Otherwise, if the new type is unsigned, the value is converted by repeatedly adding or subtracting one more than the maximum value that can be represented in the new type until the value is in the range of the new type. (60) Otherwise, the new type is signed and the value cannot be represented in it; either the result is implementation-defined or an implementation-defined signal is raised. (60) The rules describe arithmetic on the mathematical value, not the value of a given type of expression. -- ISO/IEC 9899:2011 §6.3.1.3 - Signed and Unsigned Integers
Is it copy's fault: No. It's my own damn fault for passing a bad
length there when I should be passing BUF_SIZE - 1. I, the
programmer, should know better. Period. This is just one of those things
that falls into the greater responsibility category.
Note: SIZE_MAX is defined in C99 and up. For ANSI C (C89/C90) this
will be ULONG_MAX if your C library doesn't define SIZE_MAX.
Now, let's look at the author's second solution:
What the Better String library does is create a struct that always includes the length of the string's storage. Because the length is always available to a bstring then all of its operations can be safer. The loops will terminate, the contents can be validated, and it will not have this major flaw. The bstring library also comes with a ton of operations you need with strings, like splitting, formatting, searching, and they are most likely done right and safer. There could be flaws in bstring, but it's been around a long time so those are probably minimal. They still find flaws in glibc so what's a programmer to do right? There's quite a few improved string libraries, but I like bstrlib because it fits in one file for the basics and has most of the stuff you need to deal with strings. You've already used it a bit, so in this exercise you'll go get the two files bstrlib.c and bstrlib.h from the Better String. -- Zed A. Shaw, "Learn C The Hard Way", Exercise 36: Safer Strings
Now, we see the crux of the argument. "C strings suck because they don't include the length, and I think this is a major flaw, because if I pass something that's not a string to a function which expects a string, it exhibits undefined behavior. Thus, you need to use this other string library instead because it does include the length."
Wait a minute... Yup. You guessed it. This library is basically a
string library that duplicates some of the functionality of the standard
library, and adds some new functionality, which reminds me of Pascal
or in some ways a dialect of BASIC. The main difference, is that
the use of C strings is abstracted away, hidden by a struct that
also contains a length member.
I would guess that the author would prefer Pascal strings, which look like: "<6>Hello!" as they embed the length within of the string. A lot of binary data protocols will do something similar (i.e. sending the length before the actual data). However, the whole thing in this case depends on the behavior of C strings. So, if C strings are so evil, why would the author so graciously praise a library that depends on them? Because it includes the length, of course, and because it hides all the "messy" details of C strings.
You can see that this particular function, bassigncstr
has similar functionality to the copy function, and that the loop
that actually does the copying is functionally equivalent to the
loop in the function which the author so loudly decries. This function
also makes use of the dreaded strlen, wow...
Even these strings are just as vulnerable to data corruption as plain 'ol C strings. What happens if the length gets corrupted? Well, if we were reading the data over a blocking socket, we might just block until the socket is closed, waiting for bytes that don't exist to come over the wire (because we didn't ensure the length was valid.)
Sound familiar? There are more holes in the author's logic than in half of all the termite infested homes world-wide. If, as the author states in the introduction C is "telling you the cold, hard truth", why does he now complain that the "truth" wasn't sugar-coated enough?
The rest of the book goes over some simple data structures, another section on Valgrind, and the rest is incomplete. So, let's turn our attention to the author's tirade against K&R2.
Part 11: The Crusade against K&R2
When I was a kid I read this awesome book called "The C Programming Language" by the language's creators, Brian Kernighan and Dennis Ritchie. This book taught me and many people of my generation, and a generation before, how to write C code. You talk to anyone, whether they know C or not, and they'll say, "You can't beat K&RC. It's the best C book." It is an established piece of programmer lore that is not soon to die. I myself believed that until I started writing this book. You see, K&RC is actually riddled with bugs and bad style. Its age is no excuse. These were bugs when they wrote the first printing, and the 42nd printing. I hadn't actually realized just how bad most of the code was in this book and recommended it to many people. After reading through it for just an hour I decided that it needs to be taken down from its pedestal and relegated to history rather than vaunted as state of the art. I believe it is time to lay this book to rest, but I want to use it as an exercise for you in finding hacks, attacks, defects, and bugs by going through K&RC to break all the code. That's right, you are going to destroy this sacred cow for me, and you're going to have no problem doing it. ... My criticisms here are both for educational purposes of teaching people modern C code, and to destroy the belief in [K&R2] as a item of worship that cannot be questioned. -- Zed A. Shaw, "Deconstructing K&R C"
What I get from this is: "K&R2 is old, and not written in what I feel to be the 'modern' style. Therefore it's irrelevant, and it should be replaced with this book. Because it's not 'modern' there just have to be lots of bugs, but I'll leave it up to my readers-turned-minions to do my bidding and find them."
It seems the author feels that K&R2 has some sort of holy status, much like the Bible, and that said status is undeserved because the style of K&R is not 'modern' enough. I can't wait to see the example(s)...
First, the author elaborates on his 'rationale'. Most of this paragraph isn't relevant to the subject at hand, but appears to be crafted solely to mislead the user into a false belief that K&R2 was correct and now is no longer so. The last bit of this paragraph is a nonsensical comparison. This bit is absolutely full of fallacy...
In the context of this 1970's computing style, K&RC is actually correct. As long as only trusted people run complete cohesive programs that exit and clean up all their resources then their code is fine. Where K&RC runs into problems is when the functions or code snippets are taken out of the book and used in other programs. Once you take many of these code snippets and try use them in some other program they fall apart. They then have blatant buffer overflows, bugs, and problems that a beginner will trip over. ... The best way to summarize the problem of K&RC "correctness" is with an example from English. Imagine if you have the pair of sentences, "Jack and Jill went up the hill. He fell down." Well, from context clues you know that "He" means Jack. However, if you have that sentence on its own it's not clear who "He" is. Now, if you put that sentence at the end of another sentence you can get an unclear pronoun reference: "Jack and Frank went up the hill. He fell down." Which "He" are we talking about in that sentence? -- Zed A. Shaw, "Deconstructing K&R C"
Now, we finally get down to business. Remember how I said to keep the
copy function from earlier in mind? It's back.
The following copy function is found in the very first chapter and is an example of copying two strings. Here's a new source file to demonstrate the defects in this function. In this example, I'm doing something that is fairly common: switching from using stack allocation to heap allocation with malloc. What happens is, typically malloc returns memory from the heap, and so the bytes after it are not initialized. Then you see me use a loop to accidentally initialize it wrong. This is a common defect, and one of the reasons we avoided classic style C strings in this book. You could also have this bug in programs that read from files, sockets, or other external resources. It is a very common bug, probably the most common in the world. Before the switch to heap memory, this program probably ran just fine because the stack allocated memory will probably have a '\0' character at the end on accident. In fact, it would appear to run fine almost always since it just runs and exits quickly. What's the effect of running this new program with copy used wrong? -- Zed A. Shaw, "Deconstructing K&R C"
Now ain't this an interesting premise. Let's look at an example that's been modified, compare it to the original, and use the fact that it can be broken by misuse to say that the original is somehow defective. Yet another fallacy.
The biggest problem I see in this bit of text is that the author makes wild assumptions about the state of stack memory will be, without having initialized it; and that he goes on to make similar generalizations about the heap. Let's not forget the insinuation that "modern systems" should use heap memory instead of stack memory for function-local variables...
Here's the author's example code:
#include <stdio.h>
#include <assert.h>
#include <stdlib.h>
#define MAXLINE 10 // in the book this is 1000
void copy(char to[], char from[])
{
int i;
i = 0;
while((to[i] = from[i]) != '\0')
++i;
}
int main(int argc, char *argv[])
{
int i;
// use heap memory as many modern systems do
char *line = malloc(MAXLINE);
char *longest = malloc(MAXLINE);
assert(line != NULL && longest != NULL && "memory error");
// initialize it but make a classic "off by one" error
for(i = 0; i < MAXLINE; i++) {
line[i] = 'a';
}
// cause the defect
copy(longest, line);
free(line);
free(longest);
return 0;
}
This is completely different than what's in the original code. This example is taken from K&R2, Chapter 1, Section 9, pg. 29:
#include <stdio.h>
#define MAXLINE 1000 /* maximum input line size */
int getline(char line[], int maxline);
void copy(char to[], char from[]);
/* print longest input line */
main()
{
int len; /* current line length */
int max; /* maximum length seen so far */
char line[MAXLINE]; /* current input line */
char longest[MAXLINE]; /* longest line saved here */
max = 0;
while ((len = getline(line, MAXLINE)) > 0)
if (len > max) {
max = len;
copy(longest, line);
}
if (max > 0) /* there was a line */
printf("%s", longest);
return 0;
}
/* getline: read a line into s, return length */
int getline(char s[], int lim)
{
int c, i;
for (i=O; i<lim-1 && (c=getchar())!=EOF && c!='\n'; ++i)
s[i] = c;
if (c == '\n') {
s[i] = c;
++i;
}
s[i] = '\0';
return i;
}
/*copy: copy 'from' into 'to'; assume to is big enough */
void copy(char to[], char from[])
{
int i;
i = 0;
while ((to[i] = from(i]) != '\0')
++i;
}
Notice the fact that in the author's code the getline function is
completely missing? This is what I meant when I said he'd taken this
function completely out of context.
With getline intact, the original example makes perfect sense, and
doesn't exhibit the problems the author claims exist. This is because
we know at the time copy is called, that both parameters are in fact
valid strings that have equal storage size.
The whole problem with why copy breaks in the author's code is
simply because line is not a valid string when passed to
copy. In the real world, you'd want to make sure that the
parameters are valid strings before calling copy.
Now, let's fix the author's example. With my improved copy this
code should not exhibit any of these problems that the author is
attempting to demonstrate. In fact, the only thing I've changed from
the author's example here is to add length-checking to copy, and a
printf to main so we can see that it works:
#include <stdio.h>
#include <assert.h>
#include <stdlib.h>
#define MAXLINE 10 // in the book this is 1000
void copy(char from[], char to[])
{
size_t i = 0;
while (i < MAXLINE && (to[i] = from[i]) != '\0')
i++;
to[MAXLINE - 1] = '\0';
}
int main(int argc, char *argv[])
{
int i;
// use heap memory as many modern systems do
char *line = malloc(MAXLINE);
char *longest = malloc(MAXLINE);
assert(line != NULL && longest != NULL && "memory error");
// initialize it but make a classic "off by one" error
for(i = 0; i < MAXLINE; i++) {
line[i] = 'a';
}
// cause the defect
copy(longest, line);
printf("line: %s\n", longest);
free(line);
free(longest);
return 0;
}
When you run this example, you should see it print "line:" with
either nothing, or perhaps some random garbage behind it, since
the author didn't properly initialize longest. Now, to further
test it, let's initialize it with 'A', by adding:
#include <string.h>
at the top with the other includes, and
memset(longest, 'A', MAXLINE);
after the assert call. In a real program, we'd want to use
MAXLINE - 1 of course, but I wanted to make sure that longest
doesn't end in a null byte. I expect we'll see it write out
(MAXLINE - 1) 'A's,
What do I see when I compile and run it?
line: AAAAAAAAA
Perfect. It works just as we expect it to, without breaking as the author claims. Let's see what he has to say about the K&R example as a whole:
Now, in the context of the entire program in the original K&RC example, this function will work correctly. However, the second this function is called with longest and line uninitialized, initialized wrong, without a trailing '\0' character, then you'll hit difficult to debug errors. -- Zed A. Shaw, "Deconstructing K&R C"
By his own admission, the code as specified in the book works, and
only breaks when he takes it out of context and modifies it so that
it does break. In the original, there are no paths to copy that
don't pass through getline, thus line will always have been
initialized as a proper, null-terminated string. Hence why there's no
length checking in the K&R version. It just ain't necessary.
Within copy it doesn't matter if longest has been initialized
beforehand, since it will be initialized with the contents of line
which is clearly set when copy is called. We had to add length
checking in order to make our example code work, only because
the author had removed the guarantee of a proper null-terminated
string given by getline. This only works because we know the
maximum storage size for our strings, and that longest is at
least as big as line.
He goes on to say:
This is the failing of the book. While the code works in the book, it does not work in many other situations leading to difficult to spot defects, and those are the worst kind of defects for a beginner (or expert). Instead of code that only works in this delicate balance, we will strive to create code that has a higher probability of working in any situation. -- Zed A. Shaw, "Deconstructing K&R C"
By "many other situations" I can only imagine he means "situations where one takes random functions from the book out of context and passes them uninitialized and/or invalid parameters," based on the examples he's provided.
Apparently he had reasoned this argument ahead of time:
Many people have looked at this copy function and thought that it is not defective. They claim that, as long as it's used correctly, it is correct. One person even went so far as to say, "It's not defective, it's just unsafe." Odd, since I'm sure this person wouldn't get into a car if the manufacturer said, "Our car is not defective, it's just unsafe." -- Zed A. Shaw, "Deconstructing K&R C"
I'm still waiting for the explanation as to why calling it with invalid
arguments and getting undefined behavior is incorrect... But now,
he says he'll formally prove that copy is broken. Let's see his
analysis:
However, there is a way to formally prove that this function is defective by enumerating the possible inputs and then seeing if any of them cause the while loop to never terminate. What we'll do is have two strings, A and B, and figure out what copy() does with them: A = {'a','b','\0'}; B = {'a', 'b', '\0'}; copy(A,B); A = {'a','b'}; B = {'a', 'b', '\0'}; copy(A,B); A = {'a','b','\0'}; B = {'a', 'b'}; copy(A,B); A = {'a','b'}; B = {'a', 'b'}; copy(A,B); This is all the basic permutations of strings that can be passed to the function based on whether they are terminated with a '\0' or not. To be complete I'm covering all possible permutations, even if they seem irrelevant. You may think there's no need to include permutations on A, but as you'll see in the analysis, not including A fails to find buffer overflows that are possible. We can then go through each case and determine if the while loop in copy() terminates: while-loop finds '\0' in B, copy fits in A, terminates. while-loop finds '\0' in B, overflows A, terminates. while-loop does not find '\0' in B, overflows A, does not terminate. while-loop does not find '\0' in B, overflows A, does not terminate. -- Zed A. Shaw, "Deconstructing K&R C"
The first problem with this "proof" is that not all the arguments he's
showing here for A and B (which undoubtedly correspond in some
way to copy's from and to parameters) are strings.
Remember the definition from earlier? A string must be null terminated.
Therefore 75% of his cases here are invalid as they are NOT strings, nor
do they presumably have identical storage size as in the K&R example.
The only case left is the working case. and that fails to prove that
copy is broken within the context of the K&R example code, or
any other code for that matter.
The only thing that this proves is that the function can exhibit undefined behavior if passed invalid arguments. Apparently the author has had that argument too. He follows this up with the following non-sequitur:
Some folks then defend this function (despite the proof above) by claiming that the strings in the proof aren't C strings. They want to apply an artful dodge that says "the function is not defective because you aren't giving it the right inputs", but I'm saying the function is defective because most of the possible inputs cause it to crash the software. -- Zed A. Shaw, "Deconstructing K&R C"
It's a matter of fact. Period. No dodging required.
Where in the K&R example is it possible to give an input which will
result in a non-null-terminated character array being passed as either
parameter to copy? There are no execution paths in that example
that result in that outcome.
All this whining is like saying: "If I look at any given file of your source code and pick a random function, take it out of that context, and pass it whatever I feel like, or even modify it however I like, that I should have an implicit guarantee that it won't exhibit any undefined behavior whatsoever, or it's defective."
I don't know any programming language in existence where that would be acceptable. Certainly not in C. Let's look at the next load of bull.
Another argument in favor of this copy() function is when the proponents of K&RC state that you are "just supposed to not use bad strings". Despite the mountains of empirical evidence that this is impossible in C code, they are basically correct and that's what I'm teaching in this exercise. But, instead of saying "just don't do that by checking all possible inputs", I'm advocating "just don't do that by not using this kind of function". I'll explain further. In order to confirm that all inputs to this function are valid I have to go through a code review process that involves this: Find all the places the copy() function is called. Trace backwards from that call point to where the inputs are created. Confirm that the data is created correctly. Follow the path from the creation point of the data to where it's used and confirm that no line of code alters the data. Repeat this for all paths and all branches, including all loops and if-statements involving the data. In my experience this is only possible in small programs like the little ones that K&RC has. In real software the number of possible branches you'd need to check is much too high for most people to validate, especially in a team environment where individuals have varying degrees of capability. A way to quantify this difficulty is that each branch in the code leading to a function like copy() has a 50-70% chance of causing the defect. However, if you can use a different function and avoid all of these checks then doesn't that mean the copy() function is defective by comparison? These people are right, the solution is to "just not do that" by just not using the copy() function. You can change the function to one that includes the sizes of the two strings and the problem is solved. If that's the case then the people who think "just don't do that" have just proved that the function is defective, because the simpler way to "not do that" is to use a better function. If you think copy() is valid as long as you avoid the errors I outline, and if safercopy() avoids the errors, then safercopy() is superior and copy() is defective by comparison. -- Zed A. Shaw, "Deconstructing K&R C"
I love the words, "empirical evidence," especially when not a shred of evidence has been offered to accompany them. Then, he seems to do a 180 and say that he agrees with his critics, then goes on to dodge the issue entirely by saying we should "just use something else" because "I don't want to have to check my work -- because it's too hard."
He also continues to miss the point as to why it's not necessary to pass
the lengths to copy in this particular example, and insists that
his function is superior because "it checks the length of the strings"
when in the context of the example there's absolutely no need to do so.
He then continues to say, "If you agree with the above, then you've proven my point for me." -- Yet another fallacy. He continues to moan about some "stylistic issues" which are so trivial that I'm not even going to bother addressing it. K&R already did so, before this piece was ever written.
... The position of braces is less important, although people hold passionate beliefs. We have chosen one of several popular styles. Pick a style that suits you, then use it consistently. -- Kerninghan & Ritchie, "The C Programing Language", Section 1, Page 10
Final Thoughts
Interestingly enough, just a couple weeks ago, on the 4th of January, 2015; the author removed the original version of this section from his book, and replaced it with this statement presumably "admitting defeat" in his quest to sack the temple of K&R as it were; proclaiming that "C is dead" and "curse all those pedantic C developers, I'm going to go learn Go!"
He laments:
I’ve had to battle pedants on ##c IRC channels, email chains, comments, and in every case they come up with minor tiny weird little pedantic jabs that require ever more logical modifications to my prose to convince them. ... I became actually hated. For doing nothing more than trying to teach people how to use an error prone shitty language like C safely. Something I’m pretty good at. ... I’d rather make the book useful for people who can learn C and how to make it solid than fight a bunch of closed minded conservatives who’s only joy in life is feeling like they know more about a pedantic pathetically small topic like C undefined behavior. ... Now I know that I will make the book a course in writing the best secure C code possible and breaking C code as a way to learn both C and also rigorous programming. ... But C? C’s dead. It’s the language for old programmers who want to debate section A.6.2 paragraph 4 of the undefined behavior of pointers. Good riddance. I’m going to go learn Go. ... I learn languages now to teach them to people, not because I plan on using them for anything.
My advice to the author is:
Well, if that's really what you want to do, then go for it. But, before you rewrite your C book, perhaps you should take the time to actually dig into it and learn C first (inside and out.) Then determine whether you're actually qualified to write a book on the subject. I'd say that judging by what you've written both in your book, and this particular post, that you have a long way to go before you can master how to use a "error prone shitty language like C" as you put it. If you hold C in such low regard, why the hell would you want to write a book to encourage people to learn it, anyway? It makes no sense to me. Perhaps at the time you sat down to write your book, you had a different opinion, and that opinion changed when you just couldn't be right.
Undefined behavior is not a "pathetically small topic" at all, especially when your target audience are novice programmers. I'm not suggesting you have to take it to the deepest level in your prose, but where do you think most of the security flaws in C programs come from? People coding by assumption, and evoking undefined behaviors and not realizing it or the consequences of doing so. Those "pedantic" people in the know will gladly exploit those sorts of mistakes. Hiding things behind some abstraction, and then claiming it's somehow "safer," isn't doing any favor to your readers.
If you want to write about rigourous coding, then teach people how to analyze the code and look for things like undefined behavior. Then, teach them to understand it, and finally, how to correct it. But, before putting pen to paper (or finger to keyboard as it were) you really should brush up on it youself.
Learn how to accept criticism, and admit to yourself that you're not always right. Go out and have your book peer reviewed by people who are actually writing code in C, and don't assume that they're just a bunch of pedantic assholes just because they point out that you are wrong in your assumptions. Approach the community with an eagerness to learn and do, and learn from our experience, instead of positioning yourself as someone who has to prove that the world is wrong and you are right. That won't get you anywhere in any situation. Furthermore, you will never win an argument with pedantic people by arguing from emotion. Period.
The worst part about your book in my opinion, is not the whining in circles about how K&R is old, outdated, and in your view, "wrong;" it's that you're trying to do the right thing (getting people interested in the subject) but instead of helping them, your book is grossly undermining them. Please, for the love of God, either check your facts and correct it so that it complies with the C standard, or take it offline entirely. As it is currently, you're doing your readers a great disservice.
If you don't plan on using a programming language yourself, how will you ever learn it to the extent that you should, in order to teach others? I implore you, try coming to grips with the subject matter before writing a book, and save us all a lot of headache. If you want to teach others, you have to teach yourself first.
Zed's Rebuttal
Update: 8 months following this article (Sep. 28), Zed wrote a rebuttal. He pastes excerpts from a couple of emails I wrote, but what he fails to mention is how those emails originated.
After reading this post, Zed had wrote me attempting to recruit me to be a paid technical reviewer for his book, which I had declined because I didn't really have the time to invest, and frankly didn't care. Contrary to what he may try to lead people to believe, I do in fact stand behind my opinions as written.
Here is the original email, from Zed, which began the thread way back on February 3rd:
Hey Tim, this is me Zed. Just dropping you a quick email before I actually sleep. I liked what you wrote about my book, and I actually think you may learn some things from me. I'd like you to be a technical reviewer for my book, and I'd pay you for it too.I'll write more about it tomorrow, but basically you'd take exercises as I write them and point out technical flaws or definition flaws. The book's design is actually going to change in target audience away from total newbs and more to people who need to learn secure coding and C.
That's why I mentioned your suggested copy function as problematic. It fails if the C string is malformed and the size given is of the larger string (or just too large). That's the kind of UB every C coder claims they don't need to handle, but from a secure defensive programming standpoint, it's what causes tons of defects. The reason this one particular malformed string UB is such a problem is because it's one of the few that can be controlled by an external attacker. Without sizes on both strings, an attacker can get a bad string in with an executable payload and own the process.
Anyway, the book is actually changing to be more about defensive secure programming and C. I need a technical reviewer who's not a dipshit, and you definitely don't seem like a dipshit.
If you're game, then let's talk some more tomorrow. Thanks again.
Zed
The precursor to this email was a direct message conversation on Twitter:
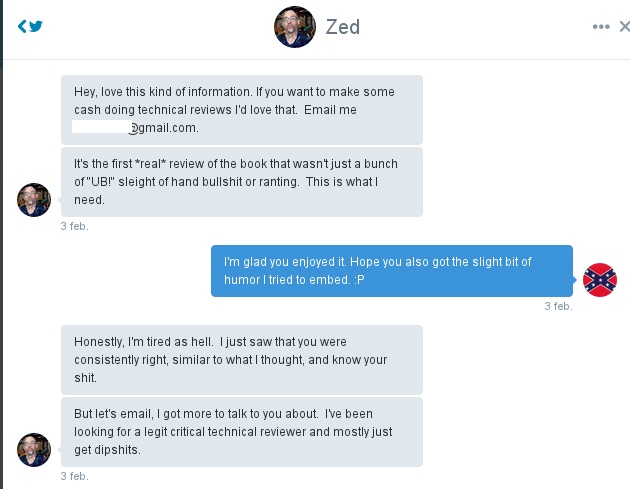
And before that Zed tweeted:
Hey @asswhup, this http://t.co/U2mgtnwGwK is fucking awesome and pretty much what I thought for my rewrite? Can we email?
— Zed (@zedshaw) 3 februari 2015Personally, I find his assertion that I lack "honesty and integrity" to be nothing more than a libelous ad hominem attack on Zed's part. He did point out one thing that is true. I did misspell recommend, and have since fixed my typo. And he is right that I'm not an author, nor a teacher, but I've never claimed to be either.
Furthermore, his new post is in direct conflict with his own statements which were written after having read this post, as you can clearly see. His book was published on Amazon (by Addison-Wesley of all places) just two weeks ago. Coincidence? I think not. Just Zed's style of self-marketing.